A paper on the PIMO Diary is
Christian Jilek, Heiko Maus, Sven Schwarz and Andreas Dengel: Diary Generation from Personal Information Models to Support Contextual Remembering and Reminiscence. In Workshop on Human Memory-Inspired Multimedia Organization and Preservation (HMMP). IEEE International Conference on Multimedia and Expo (ICME-2015), June 29 - July 3, Torino, Italy, IEEE, 2015, 1-6A version of the paper can be found here.
Introduction
PIMO Diary is probably the app in which the user experiences the benefits of forgetting and preservation in the most intuitive way that is especially also easily comprehensible by non-technophiles. A vast majority of people knows the concept of a diary whose principle is close to the human characteristic of mentally organizing memories in episodes. Remembering and reminiscing is usually aligned to so-called memory landmarks, certain events or periods which are very memorable to a person, e.g. birth, wedding, a nice holiday etc.
Using the Semantic Desktop regularly leads to a PIMO enriched with lots of semantically annotated information, e.g. documents, web pages, emails, calendar events, etc. In order to get an overview of what actually happened and what was important in a given period of time, sorting, mentally connecting, abstracting and rebuilding a context is necessary. This typically is a difficult, tedious and time-consuming task - depending on a person's memories and the (supporting) material available it might even be impossible. To solve (or at least support in solving) this problem and allow contextual remembering in ForgetIT, PIMO Diary enables a user to generate a personal (or group) diary based on the information items available in his/her PIMO.
In order to prevent the diary from being a confusing, large, sequential collection of material, we need to identify semantic relationships among possibly several thousands of individual information items and create suitable abstractions from them. If a user, for example, looks back on the last decade, he/she should not be overwhelmed with a view showing plenty of individual events, but compact statements like project names, stages of life, life situations, etc. Examples for those are terms like school years, studies, marriage or the name of a place where a vacation or longer stay abroad has been spent.
The user literally zooms out of a overwhelming mass of details. If desired, these abstractions can easily be resolved by selecting a sub-period of time for concretization (zooming in), e.g. a year of a decade or a month of a year. Concretizations (half-years, quarters, months, weeks, days) can be performed until the user reaches the actual (non-rehashed) basic material, which are the concrete information items like notes, photos, documents, etc.
The system applies a combination of merging and filtering by clustering related or very similar things to diary entries and evaluating their importance for the user. The former aspect fosters a high diversity within the diary, making it interesting and fun to read, whereas the latter aspect is a necessity induced by the fact that the number of diary entries to be generated is usually very limited. Things contribute to the diary according to their importance: more memorable (preservable) things heavily contribute and characterize or shape at least one entry, whereas rather unimportant things only weakly contribute to a related but more important entry or are completely forgotten, i.e. not represented in the current diary.
Thus, a user should be able to easily get a satisfactory retrospection on those parts of his/her life that are represented by his/her PIMO without much effort.
8.1.1. Basics
Our first video shows how a typical diary entry looks like, how the diary app is started, its navigation, and how diaries for specific periods of time are generated.
In addition, the feature of changing the sorting criteria of entries and a statistical value called the data coverage are explained. Concerning the former, the entries can either be arranged as a blog (chronologically descending, i.e. from the newest to the oldest entry), a diary (chronologically ascending), or by importance (most important entries of a selected period first). Since the number of desired diary entries for a given period of time is usually limited, possibly not all information items are actually incorporated into a diary. If this is the case, the so-called data coverage (i.e. the relation of all items included in the current diary and all items available for a given time period) is below 100%. This gives a hint to the user of how much of his data is actually represented in the current diary view.
8.1.2. Sorting out stuff
In the first video, the resulting data coverage was 34%. A value of 100% can either be achieved by iteratively increasing the number of entries to be generated (e.g. from 10 to 20) or directly by turning off the sorting out of less important things. As a consequence, information items previously sorted out by the algorithm are now incorporated into the diary in both cases.
8.1.3. Zooming in an out of time periods
In order to find just the right level of details, our diary app allows zooming in an out of time periods. The app starts at the level of weeks. We could zoom-in to reach the level of days, which is the lowest level available. To do this, we can either click on a week's entry directly or we use the zoom-in button. Depending which option we choose, a different day is chosen (in general). Clicking an entry directly brings us to the latest day covered by the entry. Using the button opens the current week's last day. So, clicking entries allows a slightly more targeted zooming in. On the level of days, no condensation is done and the different information items may be browsed directly. Clicking an item directly opens it in the specific app, e.g. a note is opened in the note app (like it is shown in the video). Using the zoom-out button the abstraction level is raised: from weeks to months, months to quarters, quarters to half-years, half-years to years, etc. In all these transitions condensation and importance filtering is applied.
8.1.4. Concept context
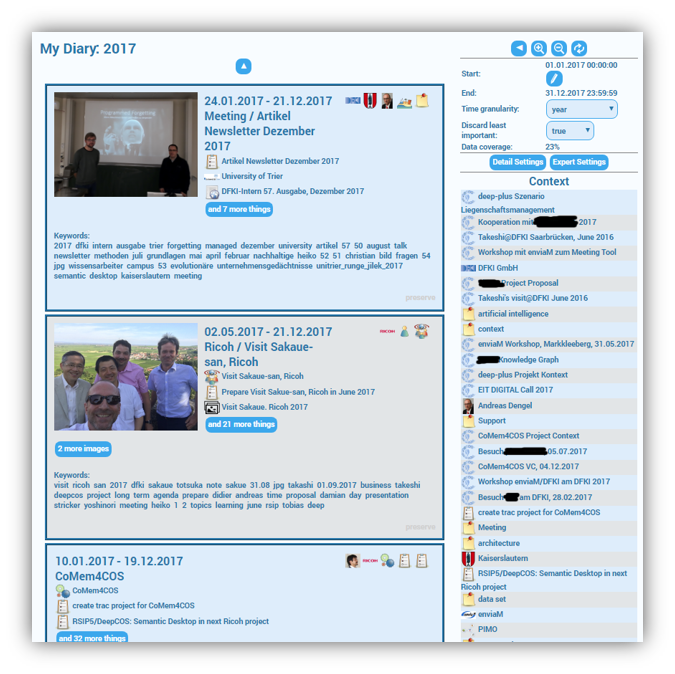
The last video showed how zooming in and out helps in determining the preferred level of details. In addition to allowing a thorough retrospection on one's life, we also wanted to provide a quick overview of the things that concerned a user the most in a given time period (based on the information provided by his/her PIMO). We therefore introduced the so-called concept context (or context for short). It can be found on the right side of the diary app's user interface and gives an impression of the (greater) context in which the current diary is embedded.
8.1.5. Fine-granular de/selection
After having created some of the videos on this page, we slightly updated the appearance of a diary entry,
making it more homogeneous.
Additionally, all items of an entry (not just the most prominent ones) can now be displayed and directly
accessed by clicking them.
The following video illustrates these updates.
Contribution to ForgetIT
The diary metaphor is a suitable application scenario for showing the benefits of the ForgetIT approach for personal preservation (for details please see ForgetIT deliverable D9.1). The diary covers various situations (such as events or travel), includes various types of material such as photos or documents, and provides services that range from daily interaction, when data is proactively processed for later preservation, to long-term reminiscence.
8.1.6. Extended Functionality
Our diary app tries to analyze the semantic interrelations between information items (e.g. person
is-manager-of project or diary is-part-of ForgetIT).
Similarities between items in terms of used words in labels and text bodies, as well as similarities in
annotations are taken into account.
The system tries to cluster related things to diary entries and at the same time does two kinds of importance
evaluation:
intra-cluster: This determines which items shape and characterize the cluster.
For example, a cluster might be about a social event like a conference, together with all data beloning to it:
a paper, a presentation, flight tickets, hotel reservation, etc.
inter-cluster: Which entries are probably the most important ones for a user in the currently chosen
period of time. To evaluate this, parameters like annotation intensity, cluster size, association with rich
media like photos or mentioning rather rare persons, locations, etc. are taken into account.
Another intention behind the clustering of similar things is to foster a high diversity of entries in the
diary, thus making the diary interesting and fun to read.
The next video shows a (debug) function called show cluster composition that reveals all elements
and therefore the composition of a cluster (or a diary entry, respectively).
(In later versions of the diary app this feature moved form "Detail Settings" to "Expert Settings".)
8.1.7. Group diary
Users have the possibility to incorporate shared data of their family, friends or colleagues - represented by a group information model (GIMO) - into their own personal diary turning it into a group diary. This video shows examples in which one user shared a photo collection with others and another case, in which additional information items complement the user's own entries.
8.1.8. Further fine-tuning
There are more options for the user to alter his diary. A user may (iteratively) demand more or less 1) diversity, 2) rare things or 3) rich media things (i.e. entries associated with a photo, for example). The following video shows an example of demanding more things associated with rich media. This influences the system's (inter-cluster) importance evaluation and after a few clicks only entries associated with photos are among the most important ones.
8.1.9. ...still in use
The PIMO is still in use at the - meanwhile renamed DFKI Smart Data & Knowledge Services Department - as you can see in this diary excerpt from 2017.